API: Experiment
Overview
An “Experiment” is the central concept in RapidFire AI to organize and streamline your multi-config AI experimentation.
Every experiment must have a unique user-given name that is used to collate plots on the ML metrics dashboard and for saving its artifacts. If you (mistakenly) reuse a previous experiment name, RapidFire AI will append a suffix akin to what filesystems do.
The Experiment class has the functions and semantics detailed below.
As of this writing, an experiment can operate in either "fit" mode or "evals" mode but not both.
We plan to allow both modes in the same experiment very soon.
Note
Only one function in this class can be run at a time. If you interrupt a long-running function,
say, run_fit() or run_evals(), wait for up to 2min for the Python threads to be
cleaned up before running another function.
Experiment Constructor
Constructor to instantiate a new experiment.
- __init__(self, experiment_name: str, mode: str = 'fit', experiment_path: str = './rapidfire_experiments') None
- Parameters:
- Returns:
None
- Return type:
None
Example:
# Based on SFT chatbot tutorial notebook
>>> experiment = Experiment(experiment_name="exp1-chatqa", mode="fit")
Experiment exp1-chatqa created ...
# Based on FiQA RAG chatbot tutorial notebook
>>> experiment = Experiment(experiment_name="exp1-fiqa", mode="evals")
Experiment exp1-fiqa created ...
Notes:
You can instantiate as many experiment objects as you want.
We recommend explicitly ending a previous experiment (see end() below) before starting
a new one so that you are cognizant of your code and/or config changes across them.
If you are using Jupyter and if its kernel restarts or gets interrupted for whatever reason, you can just reconnect the kernel and pick up that experiment from where you left off by just rerunning its constructor cell as is (unless you ended the experiment explicitly). Using that object you can continue that experiment as before.
Run Fit
The main function to launch training (including LLM fine-tuning and post-training) and evaluation for a given config group in one go. See the Multi-Config Specification page for more details on how to construct a config group.
- run_fit(self, param_config: Any, create_model_fn: Callable, train_dataset: Dataset, eval_dataset: Dataset, num_chunks: int, seed: int=42, num_gpus: int) None:
- Parameters:
param_config (Train config-group or list as described in the Multi-Config Specification page) – A train config knob dictionary, a generated config group, or a
listof configs or config groupscreate_model_fn (Callable) – User-given function to create a model instance; a single cfg is passed as input by the system
train_dataset (Dataset) – Training dataset
eval_dataset (Dataset) – Evaluation dataset to measure eval metrics
num_chunks (int) – Number of logical splits of data to control degree of concurrency for multi-config execution (recommended: at least 4)
seed (int, optional) – Seed for any randomness used in your code (default: 42)
num_gpus (int, optional) – Number of GPUs to use per run/config for each config represented in
param_config; overriden by anynum_gpusgiven inRFModelConfigfor those associated configs.
- Returns:
None
- Return type:
None
Example:
# Based on SFT chatbot tutorial notebook
>>> experiment.run_fit(config_group, sample_create_model, train_dataset, eval_dataset, num_chunks=4, seed=42)
Started 4 worker processes successfully ...
Notes:
This method auto-generates the ML metrics files as per user specification and auto-plots them on the dashboard.
Within an experiment, you can rerun run_fit() as many times as you want. All of them
will be overlaid on the same plots on the ML metrics dashboard.
Note that run_fit() must be actively running for you to be able to use Interactive Control (IC)
ops on the dashboard.
The param_config argument is very versatile in allowing you to construct various knob combinations
and launch them in one go.
It can be a single config dictionary, a list of config dictionaries, a config group generator output
(RFGridSearch() or RFRandomSearch() for now), or even a list with mix of configs or
config group generator outputs as its elements.
Please see the the Multi-Config Specification page for more details.
Each individual config is passed as input to your create_model_fn(). Inside it you can use whatever
knob you set in the config group, e.g., model type or name to instantiate a model accordingly.
You can import models from libraries such as HuggingFace transformers or load your own PyTorch checkpoints.
The num_chunks argument is a critical one that enables you to balance a higher degree of concurrency
you desire for cross-config comparisons against the (relatively minor) extra swapping overhead incurred.
We recommend at least 4, which means you will see results for all runs on 1/4th of the data at a time.
Run Evals
The main function to launch LLM evaluation (evals), including with optional RAG, for a given config group in one go. See the Multi-Config Specification page for more details on how to construct a config group.
- run_evals(self, config_group: Any, dataset: Dataset, num_shards: int=4, num_actors: int, seed: int=42) dict[int, tuple[dict, dict]]:
- Parameters:
config_group (Evals config-group or list as described in the Multi-Config Specification page) – Single evals config knob dictionary, a generated config group, or a
listof configs or config groupsdataset (Dataset) – Evaluation dataset to measure eval metrics
num_shards (int) – Number of logical splits of data to control degree of concurrency for multi-config execution (recommended: at least 4)
num_actors (int, optional) – Number of parallel worker processes per machine to control degree of concurrency; (default: number of GPUs); (recommended max 16, if machine has no GPUs)
seed (int, optional) – Seed to control randomness for online aggregation (default: 42)
- Returns:
Dictionary with a key being run/config ID and a value being a 2-tuple with a dictionary each for all aggregated metrics and all cumulative metrics
- Return type:
Example:
# Based on FiQA RAG chatbot tutorial notebook
>>> experiment.run_evals(configs=config_group, dataset=fiqa_dataset, num_shards=4, num_actors=8, seed=42)
Started 8 actor processes ...
Notes:
This method auto-generates the ML metrics as per user specification and lists them in an auto-updated table
shown on the notebook itself (and soon, on the ML metrics dashboard also).
Alongside the metrics table, the Interactive Control (IC) Ops panel will also appear on the notebook itself.
Note that run_evals() must be actively running for you to be able to use IC Ops.
Within an experiment, you can rerun run_evals() as many times as you want. All of them
will be overlaid on the same plots on the ML metrics dashboard.
The config_group argument allows you to construct various knob combinations for inference pipelines
and launch them in one go. These pipelines can involve LLMs running on your GPUs, or OpenAI API calls, or both.
Just like with run_fit() above, you can provide a single config dictionary, a list of config
dictionaries, a config group generator output (RFGridSearch() or RFRandomSearch() for now),
or even a list with mix of configs or config group generator outputs as its elements.
Please see the the Multi-Config Specification page for more details.
The num_shards argument is identical to the num_chunks argument of run_fit() above.
That is, it let you balance the degree of concurrency for cross-config comparisons against the (minor)
extra swapping overhead incurred. Again, we recommend at least 4, which means you will see results being
updated for all runs on 1/4th of the data at a time.
Unlike run_fit(), this function does have a return value. In particular, it will return a dictionary
with the run/config ID as the key. The value is a 2-tuple with a dictionary each for all aggregated metrics
and all cumulative metrics.
End
End the current experiment to clear out relevant system state and allow you to move on to a new experiment.
Please do not run this when a run_fit() is still running.
Get Runs Information
Returns metadata about all the runs from across all run_fit() invocations in the current experiment.
- get_runs_info(self) pd.DataFrame:
- Returns:
A DataFrame with the following columns: run_id, status, mlflow_run_id, completed_steps, total_steps, start_chunk_id, num_chunks_visited_curr_epoch, num_epochs_completed, error, source, ended_by, warm_started_from, config (full config dictionary)
- Return type:
pandas.DataFrame
Examples:
# Get metadata of all runs from this experiments so far; based on SFT notebook
all_runs_info = experiment.get_runs_info()
all_runs_info # Screenshot of output below

Notes:
This function is useful for programmatic post-processing and/or pre-processing of runs and their config knobs.
For instance, you can use it as part of new custom AutoML procedure to launch a new run_fit() with new config
knob values based on get_results() from past run_fit() invocations.
We plan to expand this API in the future to return other details about runs such as total runtime, GPU utilization, etc. based on feedback.
Get Results
Returns all metrics (including loss, eval loss, and any eval metrics defined) for all steps
for all runs from across all run_fit() in the current experiment.
- get_results(self) pd.DataFrame
- Returns:
A DataFrame with the following columns: run ID, step number, loss, and one column per metric plot displayed on the dashboard
- Return type:
pandas.DataFrame
Examples:
# Get results of all runs from this experiments so far; based on SFT notebook
all_results = experiment.get_results()
print(all_results.columns) # Screenshot of output below
all_results # Screenshot of output below
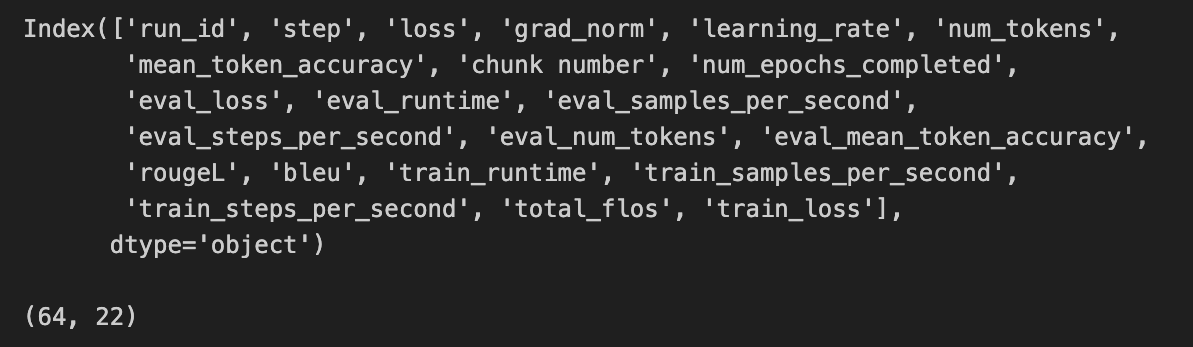

Notes:
This function can be useful for programmatic post-processing of the results of your experiments.
For instance, you can use it as part of new custom AutoML procedure if you’d like to adjust your
config for a new run_fit() based on the results of your last run_fit().