Overview of RapidFire AI Package
RapidFire AI is a new AI experiment execution framework that transforms your LLM pipeline customization from slow, sequential processes into rapid, intelligent workflows with hyperparallelized execution, dynamic real-time experiment control, and automatic backend optimization.
For RAG and context engineering evals, start here: Install and Get Started: RAG and Context Engineering.
For SFT and RFT/post-training workflows, start here: Install and Get Started: SFT/RFT.
RapidFire AI is the first system of its kind to establish live three-way communication between the IDE where the experiment is launched, a metrics display/control dashboard, and a multi-core/multi-GPU execution backend.
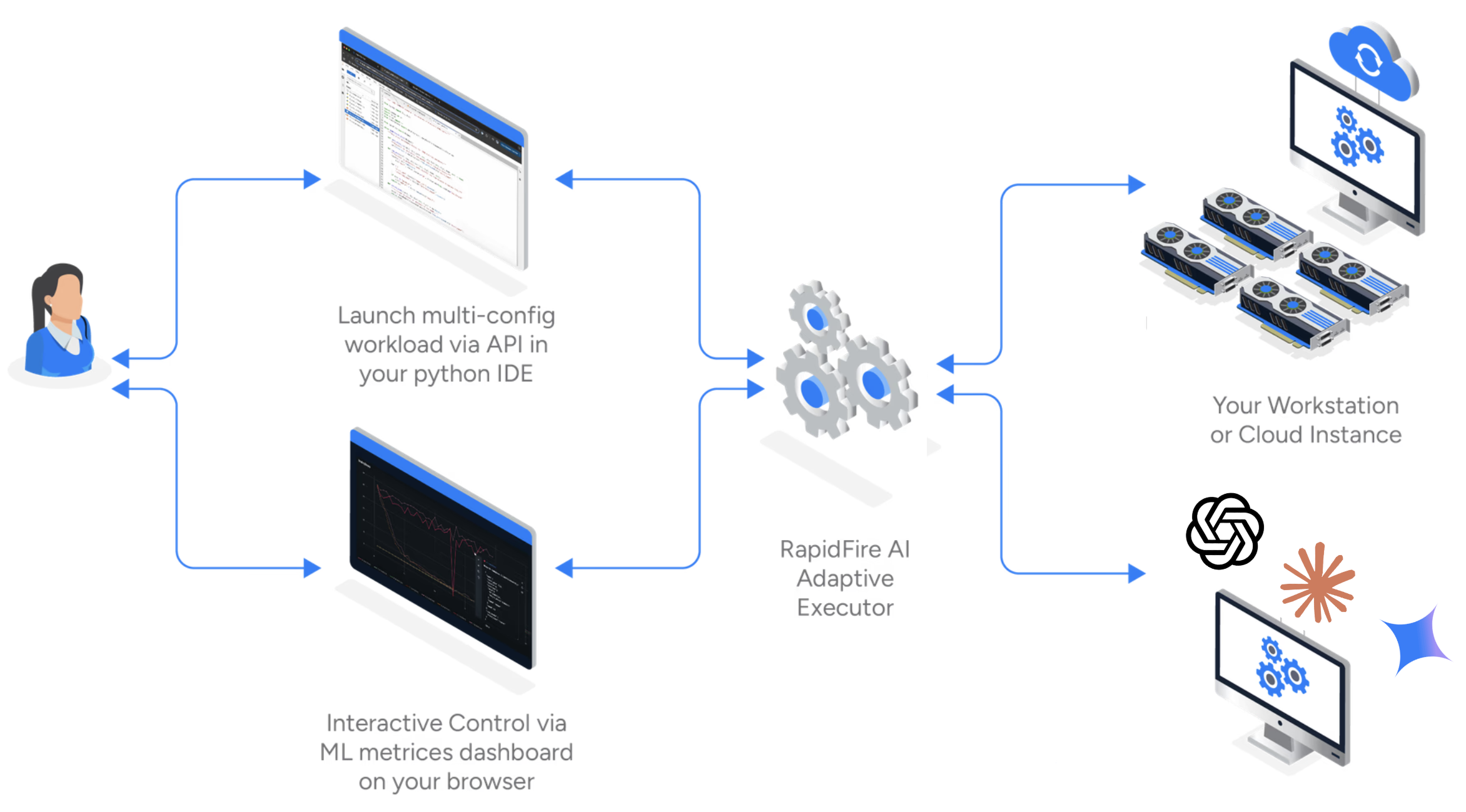
Just pip install the rapidfireai OSS package. It works on a CPU-only machine, a single-GPU machine,
or a multi-GPU machine. Note that for RAG/context engineering with only closed model APIs, GPUs are not needed.
Launch the server from the command line. Then import it as any other python package in your notebook/script. Use our API to define and launch the configs to compare in one go.
Metrics plots are automatically visualized in the ML metrics dashboard (for SFT/RFT only for now) or shown in an in-notebook take (for RAG/context eng. only for now). The Interactive Control (IC) ops panel lets you dynamically control runs in flight: stop, resume, clone, and modify them as you wish.
Check out the step-by-step walkthrough page and watch the usage video for details.
To learn more about the adaptive execution engine that differentiates RapidFire AI, powers its hyperparallelized execution, and enable IC Ops on running configs, check out this page.