API: LangChain RAG Spec
RapidFire AI’s core API for defining the stages of a RAG pipeline before the generator is a wrapper around the corresponding APIs of LangChain. In particular, this class specifies all of the following stages: data loading, chunking, embedding, indexing, retrieval, and reranking steps. Note that many of these stages are optional.
Many of the arguments (knobs) here can also be List valued or Range valued depending
on its data type, as explained below. All this forms the base set of knob combinations from which
a config group can be produced. Also read the Multi-Config Specification page.
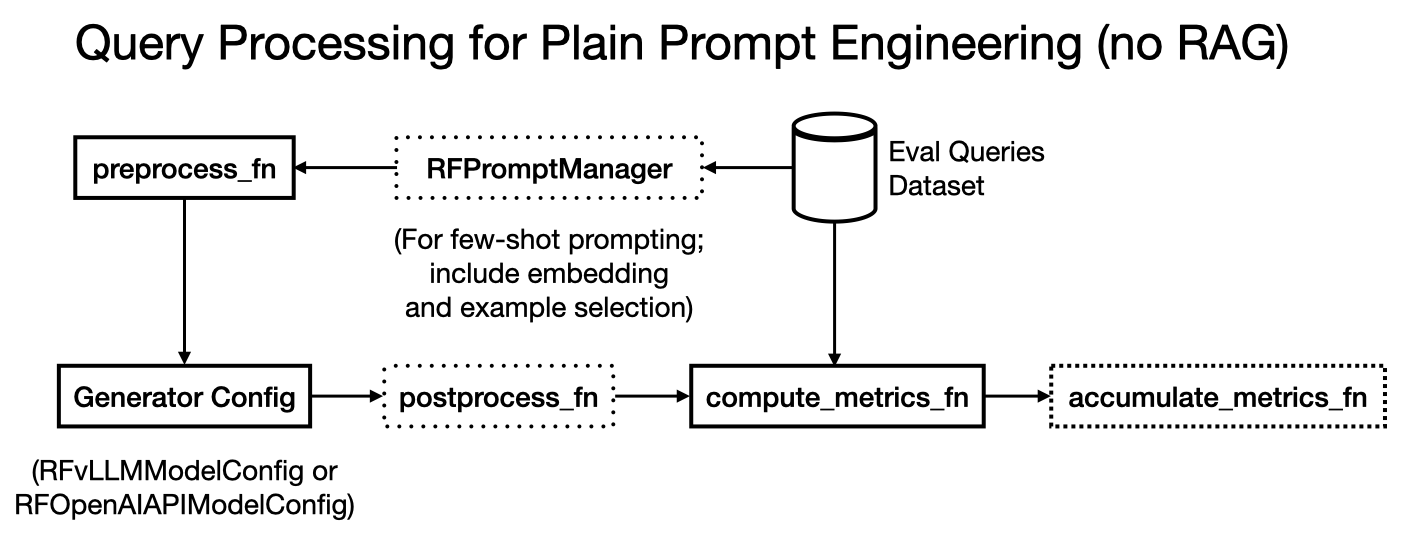
Note that for plain prompt/context engineering use cases without RAG, you can skip providing this entire class. If you’d like to do few-shot prompting instead, also read API: Prompt Manager and Other Eval Config Knobs page. Here is an illustration of the non-RAG prompt engineering workflow, with optional few-shot prompting.
RapidFire AI’s execution pipeline for RAG pipelines engineering is split into 2 main stages as illustrated in the figure below:
Document Preprocessing: Workers operate in parallel on the base data and produce preprocessed data that is stored in a vector store.
Query Processing: Workers operate in parallel on the eval set examples to embed them, retrieve relevant chunks from the vector store, rerank them, construct the full context, and then generate the outputs.
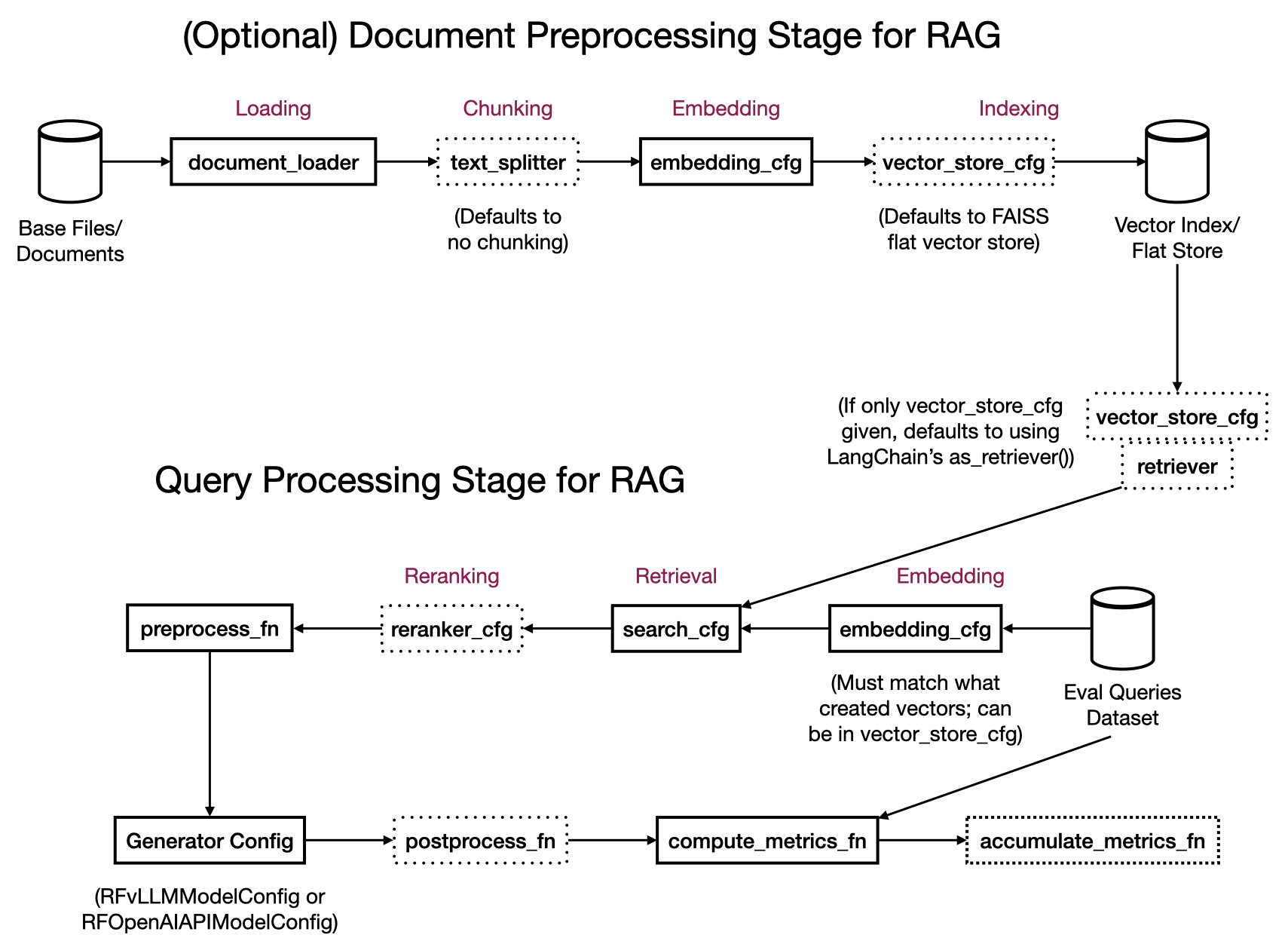
Depending on the state of your use case’s data, you can invoke only the Query Processing stage or both stages in one go via the same RFLangChainRagSpec depending on what arguments are provided:
With Preprocessing: This creates both Document Preprocessing workers and Query Processing workers. Provide
document_loader, optionaltext_splitter,embedding_cfg, and optionalvector_store_cfg. The document preprocessing workers operate on the base data, produce chunks (iftext_splitterprovided), embed the chunks (or the whole documents iftext_splitteris skipped), and store them in the vector store. Ifvector_store_cfgis not provided, RapidFire AI defaults to creating a FAISS flat vector store for you.Without Preprocessing: This creates only Query Processing workers that operate the optionally provided preprocessed vector store. Provide optional
embedding_cfgto apply to the queries (same as what produced the vector store), an optionalretrieverand/orvector_store_cfg, an optionalsearch_cfg, and an optionalreranker_cfg. Note that for plain context engineering use cases without RAG, there is no embedding, retrieval, or reranking; for few-shot prompting without RAG, you can provideembedding_cfgand similarity search knobs for the examples.
- class RFLangChainRagSpec
- __init__(document_loader: BaseLoader = None, text_splitter: TextSplitter = None, embedding_cfg: dict[str, Any] = None, vector_store_cfg: dict[str, Any] = None, retriever: BaseRetriever = None, search_cfg: dict[str, Any] = None, reranker_cfg: dict[str, Any] = None, enable_gpu_search: bool = False, document_template: Callable[[Document], str] = None)
Initialize the RAG specification with document loading, chunking, embedding, indexing, retrieval, and reranking configurations.
- Parameters:
document_loader (BaseLoader, optional) – The loader for source documents from various sources (files, directories, databases, etc.). Must be a LangChain BaseLoader implementation.
text_splitter (TextSplitter, optional) – The text splitter for chunking documents for RAG purposes. Controls chunk size, overlap, and splitting strategy. Must be a LangChain TextSplitter.
embedding_cfg (dict[str, Any], optional) – The embedding class and its kwargs to convert a chunk/query into a vector, provided as a single dictionary. Must include a key
"class"with the class itself as value, not an instance. Options for the class includeHuggingFaceEmbeddingsandOpenAIEmbeddings. The kwargs that follow must contain all parameters needed to initialize the embedding class; required parameters vary by embedding class. For example,HuggingFaceEmbeddingsneedsmodel_name,model_kwargsanddevice, whileOpenAIEmbeddingsneeds"model"and"api_key".vector_store_cfg (dict[str, Any], optional) –
The vector store type and args to store and possibly index embedding vectors for retrieval, provided as a single dictionary.
"type": The type of vector store to use. Must be one of"faiss","pgvector", or"pinecone". Required."batch_size": Number of vectors per insert batch. Applies to all 3 types of stores. Optional; default is 128.
The remaining keys are type-specific args as listed below. The vector store operates in one of 3 modes depending on the rest of the RAG spec:
Create mode: When
document_loaderis provided and no pre-existing index/collection names are specified, a new vector store is created and populated from the loaded documents.Read mode: When
document_loaderis absent and pre-existing index/collection names are specified, the vector store is opened in read-only mode for retrieval against the existing index.Update mode: When both
document_loaderand pre-existing index/collection names are provided, the existing index/collection is updated with the new documents added to it.
Supported vector store types and their arg keys:
FAISS: No additional keys. Uses a flat L2 index by default. Set
enable_gpu_search=Trueon the constructor to use GPU-accelerated FAISS. Only supports Create mode since it’s an in-memory store that is not persistent. So, the notion of pre-existing indexes does not apply.Pinecone:
"pinecone_api_key": Pinecone API key. Optional if thePINECONE_API_KEYenvironment variable is set."index_namespace": A 2-tuple of strings (tuple[str, str]) with index name and namespace. Required for Read/Update mode and must be a pre-existing index and namespace (NB: namespace can be empty string""in Pinecone). N/A for Create mode."spec": AServerlessSpecorPodSpecinstance specifying the Pinecone deployment (e.g., cloud and region). Required for Create mode. N/A for Read/Update mode."metric": Distance metric for the index, must be one of"cosine","euclidean", or"dotproduct". Optional for Create mode; default is"cosine". N/A for Read/Update mode."embedding_cfg": Embedding config dict (same format as the top-levelembedding_cfg). Required for any mode either here or in the top-level config for any mode. If provided here, this takes precedence over the top-level embedding config. For Create mode, we recommend providing it in the top-level config unless you want to couple different embedding configs with different vector stores."text_key": The metadata field name used to store the original raw text content associated with a vector in Pinecone. Optional; default is"text". Applicable to all modes. This is useful when the Pinecone index was populated by an external tool that stored text under a non-default metadata field name (e.g.,"content","original_text")."vector_type": Vector type for the index. Accepts aVectorTypevalue or string. Optional for Create mode; default is"dense". N/A for Read/Update mode."tags": Arbitrary string key-value tags to attach to the index. Optional for Create mode; default isNone. N/A for Read/Update mode."timeout": Timeout in seconds for index operations. Optional for Create mode; default isNone. N/A for Read/Update mode."deletion_protection": Whether deletion protection is enabled. Accepts aDeletionProtectionvalue or string. Optional for Create mode; default is"disabled". N/A for Read/Update mode.
To recap, for all 3 modes
"pinecone_api_key"is needed either here or as an environment variable;embedding_cfgis also required either here or in the top-level config. The"text_key"is optional for all modes and defaults to"text".For Create mode,
"spec"is required but the following are all optional:"metric","vector_type","tags","timeout", and"deletion_protection". Although the argument"index_namespace"is inapplicable, internally RapidFire AI creates an index name automatically with prefix “rf-” and an SHA hash per pre-processing worker to avoid naming conflicts; the namespace created is the default empty string.For Read/Update mode,
"index_namespace"is required and must point to a pre-existing index and namespace. All the other arguments are inapplicable.Postgres PGVector:
"connection": DB connection string or engine. Required for all modes."collection_name": A pre-existing PGVector collection/table name to use for retrieval. Required for Read/Update mode. Inapplicable to Create mode; an SHA-based random name will be generated."embedding_cfg": Same explanation as above under Pinecone."pre_delete_collection": IfTrue, deletes the collection if it already exists before writing. Use with caution. Optional; default isFalse. Applicable only to Update mode.
The store is built from the documents provided via
document_loader. If this entire config is skipped, a default FAISS flat vector store will be created automatically.retriever (BaseRetriever, optional) – The retriever for chunk retrieval. If not provided, a default FAISS vector store will be created automatically using the specified search configuration below. Must be a LangChain BaseRetriever implementation.
search_cfg (dict, optional) –
The search algorithm type and its kwargs to use for retrieval of vectors/chunks, provided as a single dictionary. Must include a key
"type"with one of the following three options listed as value; default is"similarity"."similarity": Standard cosine similarity search."similarity_score_threshold": Similarity search with minimum score threshold (SST)."mmr": Maximum Marginal Relevance (MMR) search for diversity.
Additional parameters for search configuration depend on the type; the keys can include the following:
"k": Number of documents to retrieve. Default is 5."filter": Optional filter criteria function for search results."score_threshold": Only for SST. Minimum similarity score threshold."fetch_k": Only for MMR. Number of documents to fetch before MMR reranking. Default is 20."lambda_mult": Only for MMR. Diversity parameter for MMR balancing relevance vs. diversity. Default is 0.5.
reranker_cfg (dict[str, Any], optional) – The reranker class and its kwargs for reordering retrieved chunks by relevance, provided as a single dictionary. Must include a key
"class"with the class itself as value, not an instance. Options includeCrossEncoderRerankerfromlangchain.retrievers.document_compressors. The instantiated reranker is applied to each query’s results individually. The kwargs that follow must contain all parameters needed to initialize the reranker class; required parameters vary by reranker class. For example,CrossEncoderRerankerneedsmodel_name,model_kwargsandtop_n.enable_gpu_search (bool, optional) – If
True, uses GPU-accelerated FAISS (IndexFlatL2 on GPU) with matrix multiply for exact search. Otherwise uses CPU-based FAISS HNSW index (IndexHNSWFlat) for approximate search. GPU mode requiresfaiss-gpupackage and CUDA-compatible GPU. Default isFalse.document_template (Callable[[Document], str], optional) –
Optional function to format each retrieved chunk for context injection into prompts. Should accept a single LangChain
Documentobject and return a formatted string. Multiple documents are separated by double newlines when serialized. If not provided, the following default template is used:def default_template(doc: Document) -> str: """Default document formatting template.""" metadata = "; ".join([f"{k}: {v}" for k, v in doc.metadata.items()]) return f"{metadata}:\n{doc.page_content}"
You can provide a custom template to control what metadata fields are included and how the content is formatted. For example, to include only a specific metadata field:
def sample_template(doc: Document) -> str: doc_source = doc.metadata.get("source", "") return f"Document Source: {doc_source}:\nContent: {doc.page_content}"
Or for a dataset like SciFact where documents have a
"title"metadata field ingested viametadata_funcin the document loader:def custom_template(doc: Document) -> str: return f"{doc.metadata['title']}: {doc.page_content}"
- serialize_documents(batch_docs: list[list[Document]]) list[str]
Serialize batch of context document chunks into formatted strings for context injection.
- get_context(batch_queries: list[str], use_reranker: bool = True, serialize: bool = True) list[str] | list[list[Document]]
Convenience function to retrieve and optionally also serialize relevant context document chunks for batch queries. By default, if a reranker is provided in the RAG spec it will be applied.
- Parameters:
batch_queries (list[str]) – List of query strings to retrieve context for.
use_reranker (bool, optional) – Whether to apply reranking if a reranker is provided. Default is True. Set to False to skip reranking.
serialize (bool, optional) – Whether to serialize documents into strings. If False, returns raw Document objects. Default is True.
- Returns:
List of formatted context strings (if :code:`serialize`=True) or list of Document lists (if :code:`serialize`=False), one per query.
- Return type:
- Raises:
ValueError – If retriever is not configured in RAG spec; internal method
build_index()will fail.
Examples:
# From the FiQA tutorial notebook
rag_gpu = RFLangChainRagSpec(
document_loader=DirectoryLoader(
path=str(dataset_dir / "fiqa"),
glob="corpus.jsonl",
loader_cls=JSONLoader,
loader_kwargs={
"jq_schema": ".",
"content_key": "text",
"metadata_func": lambda record, metadata: {
"corpus_id": int(record.get("_id"))
}, # store the document id
"json_lines": True,
"text_content": False,
},
sample_seed=42,
),
# 2 chunking strategies with different chunk sizes
text_splitter=List([
RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="gpt2", chunk_size=64, chunk_overlap=32
),
RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="gpt2", chunk_size=256, chunk_overlap=32
)
]),
embedding_cfg={
"class": HuggingFaceEmbeddings,
"model_name": "sentence-transformers/all-MiniLM-L6-v2",
"model_kwargs": {"device": "cuda:0"},
"encode_kwargs": {"normalize_embeddings": True, "batch_size": batch_size},
},
# FAISS is an in-memory store and only works in create mode.
vector_store_cfg={"type": "faiss"},
search_cfg={
"type": "similarity",
"k": 8
},
# 2 reranking strategies with different top-n values
reranker_cfg={
"class": CrossEncoderReranker,
"model_name": "cross-encoder/ms-marco-MiniLM-L6-v2",
"model_kwargs": {"device": "cpu"},
"top_n": List([2, 5]),
},
enable_gpu_search=True, # GPU-based exact search instead of ANN index
)
# From the SciFact tutorial notebook: custom metadata ingestion and document template
# The metadata_func in the JSONLoader controls what metadata fields are extracted from
# each source record and attached to the LangChain Document object. These fields are then
# available in doc.metadata for use in document_template, preprocess_fn, postprocess_fn, etc.
def metadata_func(record: dict, metadata: dict) -> dict:
"""Extract custom metadata fields from each source JSON record."""
metadata["corpus_id"] = int(record.get("_id"))
metadata["title"] = record.get("title", "")
return metadata
# The document_template controls how each retrieved chunk is formatted into a string
# when serialized for context injection into the prompt. Here we prepend the title.
def custom_template(doc: Document) -> str:
return f"{doc.metadata['title']}: {doc.page_content}"
rag_cpu = RFLangChainRagSpec(
document_loader=DirectoryLoader(
path="datasets/scifact/",
glob="corpus.jsonl",
loader_cls=JSONLoader,
loader_kwargs={
"jq_schema": ".",
"content_key": "text",
"metadata_func": metadata_func, # Custom metadata extraction
"json_lines": True,
"text_content": False,
},
sample_seed=42,
),
...
vector_store_cfg={"type": "faiss"},
search_cfg={"type": "similarity", "k": 10},
reranker_cfg={
...
},
document_template=custom_template, # Custom formatting using ingested metadata
)
# Based on the FiQA Pinecone tutorial notebook
spec = ServerlessSpec(cloud="gcp", region="us-central1")
# Create mode
vector_store_cfg_create={
"type": "pinecone",
"pinecone_api_key": PINECONE_API_KEY, # Or set the PINECONE_API_KEY environment variable
"spec": spec,
"metric": "cosine",
"batch_size": 1024, # documents are embedded in batches of 1024. Defaults to 128.
}
# Read and Update mode
vector_store_cfg_read_update={
"type": "pinecone", # Required
"pinecone_api_key": PINECONE_API_KEY, # Or set the PINECONE_API_KEY environment variable
"index_namespace": List([("fiqa", "chunk64"), ("fiqa", "chunk256")]), # Names of *pre-existing* pinecone indexes paired with respective namespaces
"embedding_cfg": {
"class": HuggingFaceEmbeddings,
"model_name": "sentence-transformers/all-MiniLM-L6-v2",
"model_kwargs": {"device": "cuda:0"},
"encode_kwargs": {"normalize_embeddings": True, "batch_size": 128}
},
"text_key": "original_doctext", # Metadata field name for raw text in Pinecone; defaults to "text"
}
rag_gpu = RFLangChainRagSpec(
document_loader=DirectoryLoader(
...
),
...
vector_store_cfg=vector_store_cfg_create, # Using Pinecone in create mode
)
# Based on the FiQA PGVector tutorial notebook
connection = "postgresql+psycopg://rapidfireai:rapidfireai@localhost:6024/rapidfireai"
# Create mode:
vector_store_cfg_create={
"type": "pgvector",
"connection": connection,
"batch_size": 1024, # Different from generation batch size. Defaults to 128 if not set
}
# Read and Update mode shown for illustrative purposes:
vector_store_cfg_read_update={
"type": "pgvector",
"connection": connection,
"collection_name": List(["fiqa_chunk64", "fiqa_chunk256"]), # Names of *pre-existing* pgvector collections to use for retrieval
"embedding_cfg": {
"class": HuggingFaceEmbeddings,
"model_name": "sentence-transformers/all-MiniLM-L6-v2",
"model_kwargs": {"device": "cuda:0"},
"encode_kwargs": {"normalize_embeddings": True, "batch_size": 128}
},
"pre_delete_collection": True, # Optional. Deletes the collection if already exists. Use with caution!
}
rag_gpu = RFLangChainRagSpec(
document_loader=DirectoryLoader(
...
),
...
vector_store_cfg=vector_store_cfg_create, # Using PGVector in create mode
)
Notes:
Note that one RFLangChainRagSpec object can have at most one document_loader to specify the base data.
But you can specify a List or Range (when applicable) for all the other knobs in a multi-config specification.
For instance, the example above showcases two text splitters and two rerankers with different hyperparameters.
Overall, to recap the control flow of the components are as follows:
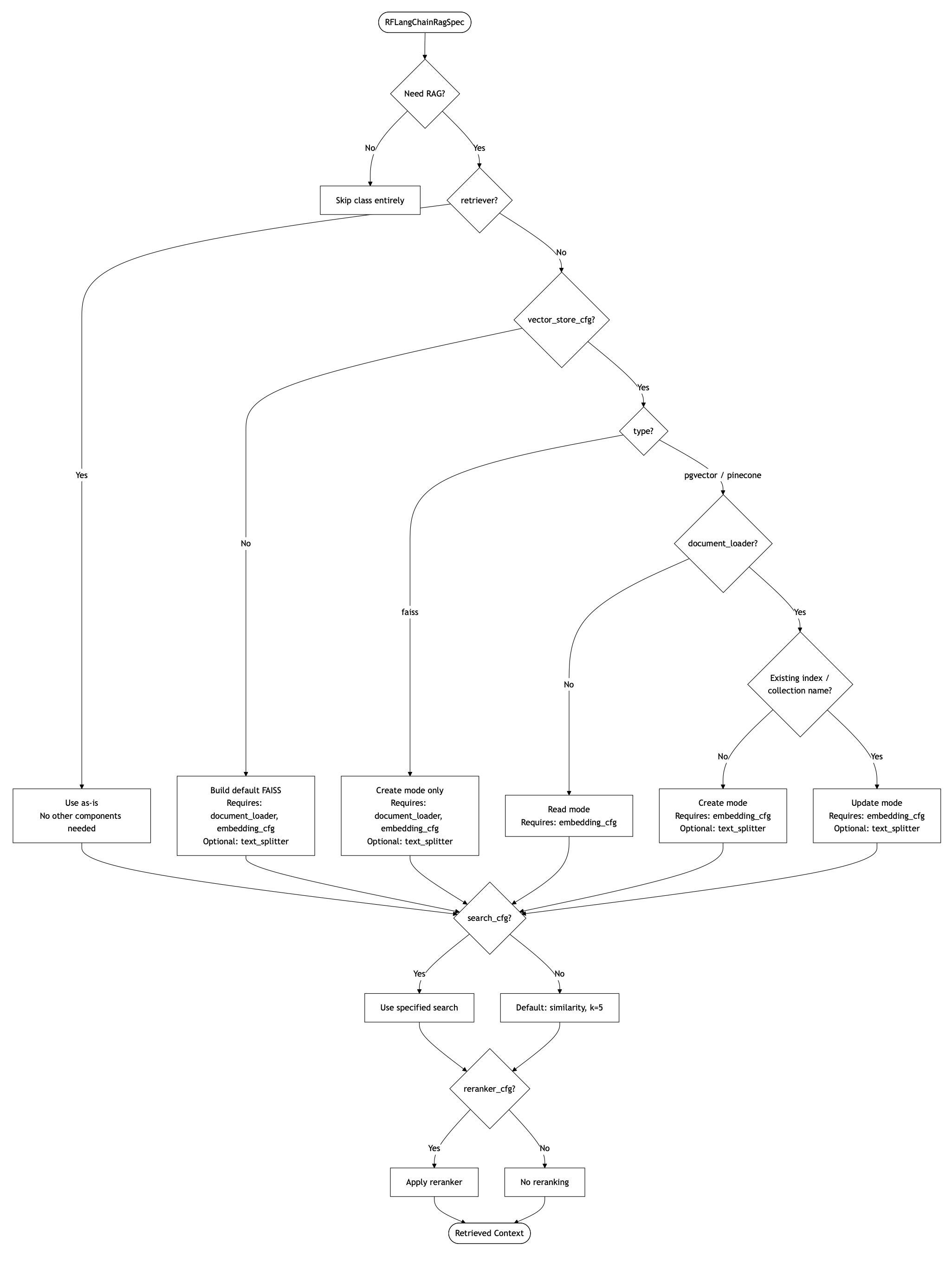
If
retrieveris provided, it is used as is. No need fordocument_loader,text_splitter, orvector_store_cfg.If no retriever but a
vector_store_cfgis provided, a retriever is created from that vector store via LangChain’sas_retriever()method and used. Theembedding_cfgis still required to embed eval queries when RAG is used; it must match the embedding model used to build the vector store for RAG. No need fordocument_loaderortext_splitterin this case for Read mode. Butdocument_loaderis required in Update mode, whiletext_splitteris optional.If neither retriever nor vector store is provided but preprocessing is needed, a default FAISS vector store (and retriever) is built from documents. In this case
document_loaderis required. Buttext_splitteris still optional: you may embed whole documents without chunking if you omit this.If
search_cfgis provided, it is used; otherwise there is a default as listed above.If
reranker_cfgis provided, it is used; otherwise no reranking is applied.If no RAG is needed and only plain prompt/context engineering is being explored, skip this class altogether. If you want to do few-shot prompting on top, check out API: Prompt Manager and Other Eval Config Knobs page.
Note
When constructing a config group with List() or Range(), the interaction of k in search_cfg with top_n in reranker_cfg has a nuance. If the assigned k is less than the assigned top_n, the combination is meaningless and will be omitted automatically by RapidFire AI. All other combinations will create valid runs. For example, if k is List([5, 10])() and top_n is List([5, 6])(), then in the 2 x 2 grid obtained, the combination k = 5 and top_n = 6 will be automatically omitted but the other 3 will be valid.
Finally, here is a comprehensive flowchart explaining the control flow of all the components and arguments in the RAG spec based on what you need for your use case.